

The Evolution of Bugs
Unlock the secrets of debugging in software development. Dive deep into state bugs, thread issues, race conditions, and performance pitfalls.

Entrepreneur, author, blogger, open source hacker, speaker, Java rockstar, developer advocate and more. ex-Sun/Oracle guy with 30 years of professional development experience. Shai built virtual machines, development tools, mobile phone environments, banking systems, startup/enterprise backends, user interfaces, development frameworks and much more. Shai is an award winning highly rated speaker with a knack for engaging the audience and deep technical chops.
Programming, regardless of the era, has been riddled with bugs that vary in nature but often remain consistent in their basic problems. Whether we're talking about mobile, desktop, server, or different operating systems and languages, bugs have always been a constant challenge. Here's a dive into the nature of these bugs and how we can tackle them effectively.
As a sidenote, if you like the content of this and the other posts in this series check out my Debugging book that covers this subject. If you have friends that are learning to code I'd appreciate a reference to my Java Basics book. If you want to get back to Java after a while check out my Java 8 to 21 book.
Memory Management: The Past and The Present
Memory management, with its intricacies and nuances, has always posed unique challenges for developers. Debugging memory issues, in particular, has transformed considerably over the decades. Here's a dive into the world of memory-related bugs and how debugging strategies have evolved.
The Classic Challenges: Memory Leaks and Corruption
In the days of manual memory management, one of the primary culprits behind application crashes or slowdowns was the dreaded memory leak. This would occur when a program consumed memory but failed to release it back to the system, leading to eventual resource exhaustion.
Debugging such leaks was tedious. Developers would pour over code, looking for allocations without corresponding deallocations. Tools like Valgrind or Purify were often employed, which would track memory allocations and highlight potential leaks. They provided valuable insights but came with their own performance overheads.
Memory corruption was another notorious issue. When a program wrote data outside the boundaries of allocated memory, it would corrupt other data structures, leading to unpredictable program behavior. Debugging this required understanding the entire flow of the application and checking each memory access.
Enter Garbage Collection: A Mixed Blessing
The introduction of garbage collectors (GC) in languages brought in its own set of challenges and advantages. On the bright side, many manual errors were now handled automatically. The system would clean up objects not in use, drastically reducing memory leaks.
However, new debugging challenges arose. For instance, in some cases, objects remained in memory because unintentional references prevented the GC from recognizing them as garbage. Detecting these unintentional references became a new form of memory leak debugging. Tools like Java's VisualVM or .NET's Memory Profiler emerged to help developers visualize object references and track down these lurking references.
Memory Profiling: The Contemporary Solution
Today, one of the most effective methods for debugging memory issues is memory profiling. These profilers provide a holistic view of an application's memory consumption. Developers can see which parts of their program consume the most memory, track allocation and deallocation rates, and even detect memory leaks.
Some profilers can also detect potential concurrency issues, making them invaluable in multi-threaded applications. They help bridge the gap between the manual memory management of the past and the automated, concurrent future.
Concurrency: A Double-Edged Sword
Concurrency, the art of making software execute multiple tasks in overlapping periods, has transformed how programs are designed and executed. However, with the myriad of benefits it introduces, like improved performance and resource utilization, concurrency also presents unique and often challenging debugging hurdles. Let's delve deeper into the dual nature of concurrency in the context of debugging.
The Bright Side: Predictable Threading
Managed languages, those with built-in memory management systems, have been a boon to concurrent programming. Languages like Java or C# made threading more approachable and predictable, especially for applications that require simultaneous tasks but not necessarily high-frequency context switches. These languages provide in-built safeguards and structures, helping developers avoid many pitfalls that previously plagued multi-threaded applications.
Moreover, tools and paradigms, such as promises in JavaScript, have abstracted away much of the manual overhead of managing concurrency. These tools ensure smoother data flow, handle callbacks, and aid in better structuring asynchronous code, making potential bugs less frequent.
The Murky Waters: Multi-Container Concurrency
However, as technology progressed, the landscape became more intricate. Now, we're not just looking at threads within a single application. Modern architectures often involve multiple concurrent containers, microservices, or functions, especially in cloud environments, all potentially accessing shared resources.
When multiple concurrent entities, perhaps running on separate machines or even data centers, try to manipulate shared data, the debugging complexity escalates. Issues arising from these scenarios are far more challenging than traditional localized threading issues. Tracing a bug may involve traversing logs from multiple systems, understanding inter-service communication, and discerning the sequence of operations across distributed components.
Reproducing The Elusive: Threading Bugs
Thread-related problems have earned a reputation for being some of the hardest to solve. One of the primary reasons is their often non-deterministic nature. A multi-threaded application may run smoothly most of the time but occasionally produce an error under specific conditions, which can be exceptionally challenging to reproduce.
One approach to identify such elusive issues is logging the current thread and/or stack within potentially problematic code blocks. By observing logs, developers can spot patterns or anomalies that hint at concurrency violations. Furthermore, tools that create "markers" or labels for threads can help in visualizing the sequence of operations across threads, making anomalies more evident.
Deadlocks, where two or more threads indefinitely wait for each other to release resources, although tricky, can be more straightforward to debug once identified. Modern debuggers can highlight which threads are stuck, waiting for which resources, and which other threads are holding them.
In contrast, livelocks present a more deceptive problem. Threads involved in a livelock are technically operational, but they're caught in a loop of actions that render them effectively unproductive. Debugging this requires meticulous observation, often stepping through each thread's operations to spot a potential loop or repeated resource contention without progress.
Race Conditions: The Ever-Present Ghost
One of the most notorious concurrency-related bugs is the race condition. It occurs when software's behavior becomes erratic due to the relative timing of events, like two threads trying to modify the same piece of data. Debugging race conditions involves a paradigm shift: one shouldn't view it just as a threading issue but as a state issue. Some effective strategies involve field watchpoints, which trigger alerts when particular fields are accessed or modified, allowing developers to monitor unexpected or premature data changes.
The Pervasiveness of State Bugs
Software, at its core, represents and manipulates data. This data can represent everything from user preferences and current context to more ephemeral states, like the progress of a download. The correctness of software heavily relies on managing these states accurately and predictably. State bugs, which arise from incorrect management or understanding of this data, are among the most common and treacherous issues developers face. Let's delve deeper into the realm of state bugs and understand why they're so pervasive.
What Are State Bugs?
State bugs manifest when the software enters an unexpected state, leading to malfunction. This might mean a video player that believes it's playing while paused, an online shopping cart that thinks it's empty when items have been added, or a security system that assumes it's armed when it's not.
From Simple Variables to Complex Data Structures
One reason state bugs are so widespread is the breadth and depth of data structures involved. It's not just about simple variables. Software systems manage vast, intricate data structures like lists, trees, or graphs. These structures can interact, affecting one another's states. An error in one structure, or a misinterpreted interaction between two structures, can introduce state inconsistencies.
Interactions and Events: Where Timing Matters
Software rarely acts in isolation. It responds to user input, system events, network messages, and more. Each of these interactions can change the state of the system. When multiple events occur closely together or in an unexpected order, they can lead to unforeseen state transitions.
Consider a web application handling user requests. If two requests to modify a user's profile come almost simultaneously, the end state might depend heavily on the precise ordering and processing time of these requests, leading to potential state bugs.
Persistence: When Bugs Linger
State doesn't always reside temporarily in memory. Much of it gets stored persistently, be it in databases, files, or cloud storage. When errors creep into this persistent state, they can be particularly challenging to rectify. They linger, causing repeated issues until detected and addressed.
For example, if a software bug erroneously marks an e-commerce product as "out of stock" in the database, it will consistently present that incorrect status to all users until the incorrect state is fixed, even if the bug causing the error has been resolved.
Concurrency Compounds State Issues
As software becomes more concurrent, managing state becomes even more of a juggling act. Concurrent processes or threads may try to read or modify shared state simultaneously. Without proper safeguards like locks or semaphores, this can lead to race conditions, where the final state depends on the precise timing of these operations.
Tools and Strategies to Combat State Bugs
To tackle state bugs, developers have an arsenal of tools and strategies:
Unit Tests: These ensure individual components handle state transitions as expected.
State Machine Diagrams: Visualizing potential states and transitions can help in identifying problematic or missing transitions.
Logging and Monitoring: Keeping a close eye on state changes in real time can offer insights into unexpected transitions or states.
Database Constraints: Using database-level checks and constraints can act as a final line of defense against incorrect persistent states.
Exceptions: The Noisy Neighbor
When navigating the labyrinth of software debugging, few things stand out quite as prominently as exceptions. They are, in many ways, like a noisy neighbor in an otherwise quiet neighborhood: impossible to ignore and often disruptive. But just as understanding the reasons behind a neighbor's raucous behavior can lead to a peaceful resolution, diving deep into exceptions can pave the way for a smoother software experience.
What Are Exceptions?
At their core, exceptions are disruptions in the normal flow of a program. They occur when the software encounters a situation it wasn't expecting or doesn't know how to handle. Examples include attempting to divide by zero, accessing a null reference, or failing to open a file that doesn't exist.
The Informative Nature of Exceptions
Unlike a silent bug that might cause software to produce incorrect results without any overt indications, exceptions are typically loud and informative. They often come with a stack trace, pinpointing the exact location in the code where the issue arose. This stack trace acts as a map, guiding developers directly to the problem's epicenter.
Causes of Exceptions
There's a myriad of reasons why exceptions might occur, but some common culprits include:
Input Errors: Software often makes assumptions about the kind of input it will receive. When these assumptions are violated, exceptions can arise. For instance, a program expecting a date in the format "MM/DD/YYYY" might throw an exception if given "DD/MM/YYYY" instead.
Resource Limitations: If the software tries to allocate memory when none is available or opens more files than the system allows, exceptions can be triggered.
External System Failures: When software depends on external systems, like databases or web services, failures in these systems can lead to exceptions. This could be due to network issues, service downtimes, or unexpected changes in the external systems.
Programming Errors: These are straightforward mistakes in the code. For instance, trying to access an element beyond the end of a list or forgetting to initialize a variable.
Handling Exceptions: A Delicate Balance
While it's tempting to wrap every operation in try-catch blocks and suppress exceptions, such a strategy can lead to more significant problems down the road. Silenced exceptions can hide underlying issues that might manifest in more severe ways later.
Best practices recommend:
Graceful Degradation: If a non-essential feature encounters an exception, allow the main functionality to continue working while perhaps disabling or providing alternative functionality for the affected feature.
Informative Reporting: Rather than displaying technical stack traces to end-users, provide friendly error messages that inform them of the problem and potential solutions or workarounds.
Logging: Even if an exception is handled gracefully, it's essential to log it for developers to review later. These logs can be invaluable in identifying patterns, understanding root causes, and improving the software.
Retry Mechanisms: For transient issues, like a brief network glitch, implementing a retry mechanism can be effective. However, it's crucial to distinguish between transient and persistent errors to avoid endless retries.
Proactive Prevention
Like most issues in software, prevention is often better than cure. Static code analysis tools, rigorous testing practices, and code reviews can help identify and rectify potential causes of exceptions before the software even reaches the end user.
Faults: Beyond the Surface
When a software system falters or produces unexpected results, the term "fault" often comes into the conversation. Faults, in a software context, refer to the underlying causes or conditions that lead to an observable malfunction, known as an error. While errors are the outward manifestations we observe and experience, faults are the underlying glitches in the system, hidden beneath layers of code and logic. To understand faults and how to manage them, we need to dive deeper than the superficial symptoms and explore the realm below the surface.
What Constitutes a Fault?
A fault can be seen as a discrepancy or flaw within the software system, be it in the code, data, or even the software's specification. It's like a broken gear within a clock. You may not immediately see the gear, but you'll notice the clock's hands aren't moving correctly. Similarly, a software fault may remain hidden until specific conditions bring it to the surface as an error.
Origins of Faults
Design Shortcomings: Sometimes, the very blueprint of the software can introduce faults. This might stem from misunderstandings of requirements, inadequate system design, or failure to foresee certain user behaviors or system states.
Coding Mistakes: These are the more "classic" faults where a developer might introduce bugs due to oversights, misunderstandings, or simply human error. This can range from off-by-one errors, incorrectly initialized variables, to complex logic errors.
External Influences: Software doesn't operate in a vacuum. It interacts with other software, hardware, and the environment. Changes or failures in any of these external components can introduce faults into a system.
Concurrency Issues: In modern multi-threaded and distributed systems, race conditions, deadlocks, or synchronization issues can introduce faults that are particularly hard to reproduce and diagnose.
Detecting and Isolating Faults
Unearthing faults requires a combination of techniques:
Testing: Rigorous and comprehensive testing, including unit, integration, and system testing, can help identify faults by triggering the conditions under which they manifest as errors.
Static Analysis: Tools that examine the code without executing it can identify potential faults based on patterns, coding standards, or known problematic constructs.
Dynamic Analysis: By monitoring the software as it runs, dynamic analysis tools can identify issues like memory leaks or race conditions, pointing to potential faults in the system.
Logs and Monitoring: Continuous monitoring of software in production, combined with detailed logging, can offer insights into when and where faults manifest, even if they don't always cause immediate or overt errors.
Addressing Faults
Correction: This involves fixing the actual code or logic where the fault resides. It's the most direct approach but requires accurate diagnosis.
Compensation: In some cases, especially with legacy systems, directly fixing a fault might be too risky or costly. Instead, additional layers or mechanisms might be introduced to counteract or compensate for the fault.
Redundancy: In critical systems, redundancy can be used to mask faults. For example, if one component fails due to a fault, a backup can take over, ensuring continuous operation.
The Value of Learning from Faults
Every fault presents a learning opportunity. By analyzing faults, their origins, and their manifestations, development teams can improve their processes, making future versions of the software more robust and reliable. Feedback loops, where lessons from faults in production inform earlier stages of the development cycle, can be instrumental in creating better software over time.
Thread Bugs: Unraveling the Knot
In the vast tapestry of software development, threads represent a potent yet intricate tool. While they empower developers to create highly efficient and responsive applications by executing multiple operations simultaneously, they also introduce a class of bugs that can be maddeningly elusive and notoriously hard to reproduce: thread bugs.
This is such a difficult problem that some platforms eliminated the concept of threads entirely. This created a performance problem in some cases or shifted the complexity of concurrency to a different area. These are inherent complexities and while the platform can alleviate some of the difficulties, the core complexity is inherent and unavoidable.
A Glimpse into Thread Bugs
Thread bugs emerge when multiple threads in an application interfere with each other, leading to unpredictable behavior. Because threads operate concurrently, their relative timing can vary from one run to another, causing issues that might appear sporadically.
The Common Culprits Behind Thread Bugs
Race Conditions: This is perhaps the most notorious type of thread bug. A race condition occurs when the behavior of a piece of software depends on the relative timing of events, such as the order in which threads reach and execute certain sections of code. The outcome of a race can be unpredictable, and tiny changes in the environment can lead to vastly different results.
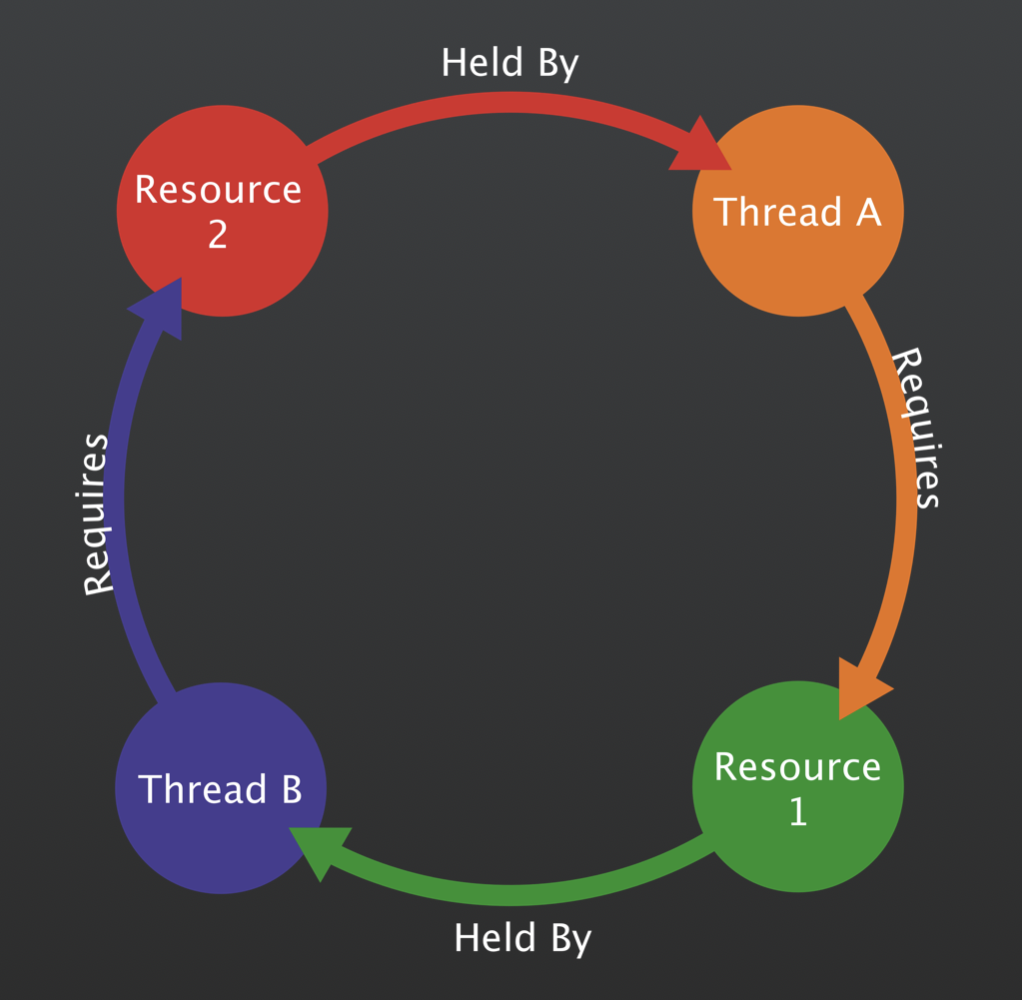
Deadlocks: These occur when two or more threads are unable to proceed with their tasks because they're each waiting for the other to release some resources. It's the software equivalent of a stand-off, where neither side is willing to budge.
Starvation: In this scenario, a thread is perpetually denied access to resources and thus can't make progress. While other threads might be operating just fine, the starved thread is left in the lurch, causing parts of the application to become unresponsive or slow.
Thread Thrashing: This happens when too many threads are competing for the system's resources, causing the system to spend more time switching between threads than actually executing them. It's like having too many chefs in a kitchen, leading to chaos rather than productivity.
Diagnosing the Tangle
Spotting thread bugs can be quite challenging due to their sporadic nature. However, some tools and strategies can help:
Thread Sanitizers: These are tools specifically designed to detect thread-related issues in programs. They can identify problems like race conditions and provide insights into where the issues are occurring.
Logging: Detailed logging of thread behavior can help identify patterns that lead to problematic conditions. Timestamped logs can be especially useful in reconstructing the sequence of events.
Stress Testing: By artificially increasing the load on an application, developers can exacerbate thread contention, making thread bugs more apparent.
Visualization Tools: Some tools can visualize thread interactions, helping developers see where threads might be clashing or waiting on each other.
Untangling the Knot
Addressing thread bugs often requires a blend of preventive and corrective measures:
Mutexes and Locks: Using mutexes or locks can ensure that only one thread accesses a critical section of code or resource at a time. However, overusing them can lead to performance bottlenecks, so they should be used judiciously.
Thread-safe Data Structures: Instead of retrofitting thread safety onto existing structures, using inherently thread-safe structures can prevent many thread-related issues.
Concurrency Libraries: Modern languages often come with libraries designed to handle common concurrency patterns, reducing the likelihood of introducing thread bugs.
Code Reviews: Given the complexity of multithreaded programming, having multiple eyes review thread-related code can be invaluable in spotting potential issues.
Race Conditions: Always a Step Ahead
The digital realm, while primarily rooted in binary logic and deterministic processes, is not exempt from its share of unpredictable chaos. One of the primary culprits behind this unpredictability is the race condition, a subtle foe that always seems to be one step ahead, defying the predictable nature we expect from our software.
What Exactly is a Race Condition?
A race condition emerges when two or more operations must execute in a sequence or combination to operate correctly, but the system's actual execution order is not guaranteed. The term "race" perfectly encapsulates the problem: these operations are in a race, and the outcome depends on who finishes first. If one operation 'wins' the race in one scenario, the system might work as intended. If another 'wins' in a different run, chaos might ensue.
Why are Race Conditions so Tricky?
Sporadic Occurrence: One of the defining characteristics of race conditions is that they don't always manifest. Depending on a myriad of factors such as system load, available resources, or even sheer randomness, the outcome of the race can differ, leading to a bug that's incredibly hard to reproduce consistently.
Silent Errors: Sometimes, race conditions don't crash the system or produce visible errors. Instead, they might introduce minor inconsistencies—data might be slightly off, a log entry might get missed, or a transaction might not get recorded.
Complex Interdependencies: Often, race conditions involve multiple parts of a system or even multiple systems. Tracing the interaction that causes the problem can be like finding a needle in a haystack.
Guarding Against the Unpredictable
While race conditions might seem like unpredictable beasts, various strategies can be employed to tame them:
Synchronization Mechanisms: Using tools like mutexes, semaphores, or locks can enforce a predictable order of operations. For example, if two threads are racing to access a shared resource, a mutex can ensure that only one gets access at a time.
Atomic Operations: These are operations that run completely independently of any other operations and are uninterruptible. Once they start, they run straight through to completion without being stopped, altered, or interfered with.
Timeouts: For operations that might hang or get stuck due to race conditions, setting a timeout can be a useful fail-safe. If the operation doesn't complete within the expected time frame, it's terminated to prevent it from causing further issues.
Avoid Shared State: By designing systems that minimize shared state or shared resources, the potential for races can be significantly reduced.
Testing for Races
Given the unpredictable nature of race conditions, traditional debugging techniques often fall short. However:
Stress Testing: Pushing the system to its limits can increase the likelihood of race conditions manifesting, making them easier to spot.
Race Detectors: Some tools are designed to detect potential race conditions in code. They can't catch everything, but they can be invaluable in spotting obvious issues.
Code Reviews: Human eyes are excellent at spotting patterns and potential pitfalls. Regular reviews, especially by those familiar with concurrency issues, can be a strong defense against race conditions.
Performance Pitfalls: Monitor Contention and Resource Starvation
Performance optimization is at the heart of ensuring that software runs efficiently and meets the expected requirements of end users. However, two of the most overlooked yet impactful performance pitfalls developers face are monitor contention and resource starvation. By understanding and navigating these challenges, developers can significantly enhance software performance.
Monitor Contention: A Bottleneck in Disguise
Monitor contention occurs when multiple threads attempt to acquire a lock on a shared resource but only one succeeds, causing the others to wait. This creates a bottleneck as multiple threads are contending for the same lock, slowing down the overall performance.
Why It's Problematic
Delays and Deadlocks: Contention can cause significant delays in multi-threaded applications. Worse, if not managed correctly, it can even lead to deadlocks where threads wait indefinitely.
Inefficient Resource Utilization: When threads are stuck waiting, they aren't doing productive work, leading to wasted computational power.
Mitigation Strategies
Fine-grained Locking: Instead of having a single lock for a large resource, divide the resource and use multiple locks. This reduces the chances of multiple threads waiting for a single lock.
Lock-Free Data Structures: These structures are designed to manage concurrent access without locks, thus avoiding contention altogether.
Timeouts: Set a limit on how long a thread will wait for a lock. This prevents indefinite waiting and can help in identifying contention issues.
Resource Starvation: The Silent Performance Killer
Resource starvation arises when a process or thread is perpetually denied the resources it needs to perform its task. While it's waiting, other processes might continue to grab available resources, pushing the starving process further down the queue.
The Impact
Degraded Performance: Starved processes or threads slow down, causing the system's overall performance to dip.
Unpredictability: Starvation can make system behavior unpredictable. A process that should typically complete quickly might take much longer, leading to inconsistencies.
Potential System Failure: In extreme cases, if essential processes are starved for critical resources, it might lead to system crashes or failures.
Solutions to Counteract Starvation
Fair Allocation Algorithms: Implement scheduling algorithms that ensure each process gets a fair share of resources.
Resource Reservation: Reserve specific resources for critical tasks, ensuring they always have what they need to function.
Prioritization: Assign priorities to tasks or processes. While this might seem counterintuitive, ensuring critical tasks get resources first can prevent system-wide failures. However, be cautious, as this can sometimes lead to starvation for lower-priority tasks.
The Bigger Picture
Both monitor contention and resource starvation can degrade system performance in ways that are often hard to diagnose. A holistic understanding of these issues, paired with proactive monitoring and thoughtful design, can help developers anticipate and mitigate these performance pitfalls. This not only results in faster and more efficient systems but also in a smoother and more predictable user experience.
Final Word
Bugs, in their many forms, will always be a part of programming. But with a deeper understanding of their nature and the tools at our disposal, we can tackle them more effectively. Remember, every bug unraveled adds to our experience, making us better equipped for future challenges.
In previous posts in the blog I delved into some of the tools and techniques mentioned in this post.




